AMMA: Adaptive Multimodal Assistants
Jackie (Junrui) Yang, Leping Qiu, Emmanuel Angel Corona-Moreno, Louisa Shi, Hung Bui, Monica S. Lam, James A. Landay
Introduction
Augmented reality (AR) has the potential to revolutionize how we learn and perform tasks by providing intelligent guidance systems. However, most current AR guidance systems are not yet adaptive to users’ progress, preferences, and capabilities. They rely on rigid, step-by-step, predefined instructions that do not account for real-world situations where users may make mistakes, have varying skill levels, or prefer different communication modalities. To address these challenges, we present Adaptive Multimodal Assistants (AMMA), a software architecture for generating adaptive interfaces from step-by-step instructions. AMMA achieves adaptivity through 1) an automatically generated user action state tracker and 2) a guidance planner that leverages a continuously trained user model.
Adaptivity: Progress, Preference, Capability
AMMA aims to provide adaptivity in three key areas:
- Progress: AMMA’s state tracker monitors the user’s actions, detects mistakes, and generates possible next steps to help the user recover and continue the task.
- Preference: AMMA learns the user’s communication preferences and guides them using their preferred modality (e.g., visual, audio, or text instructions).
- Capability: AMMA adapts to the user’s capabilities based on their observed behavior and offers instructions that maximize their performance.
Prior work in adaptive guidance systems often relies on developers’ experience and research to map specific observations (e.g., user stress level or timeout) to interface adjustments (e.g., changing the level of detail in instructions). This approach does not generalize well to different tasks and users.
AMMA’s Approach: User Modeling and Guidance Planning
AMMA takes a different approach by using machine learning to train a user model that captures the user’s preferences and capabilities. The user model is then used by a guidance planner to choose the best adjustments for the user in real-time. This approach allows AMMA to optimize for the user’s target goals (e.g., speed and taste in cooking, quality of work in writing/drawing) rather than relying on predefined mappings.
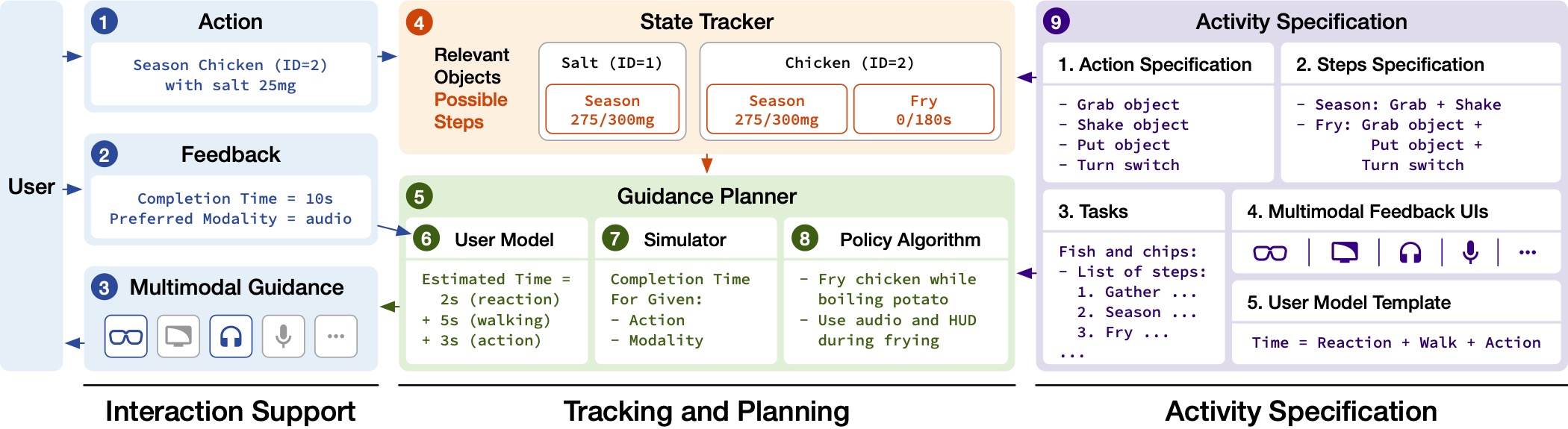
AMMA’s Architecture
AMMA’s architecture consists of three main components:
- Activity Specification: Developers provide a specification of the activity domain, including action types, step types, tasks, multimodal feedback UIs, and a user model template.
- State Tracker: AMMA automatically generates a state tracker that monitors the user’s actions, handles out-of-order actions, and helps users correct mistakes.
- Guidance Planner: AMMA’s guidance planner uses the user model and a simulator to generate a policy that maximizes the user’s performance and adapts to their preferences.
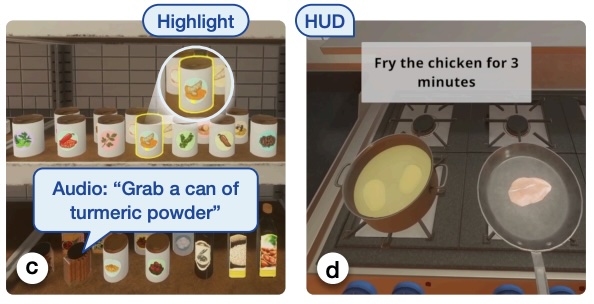
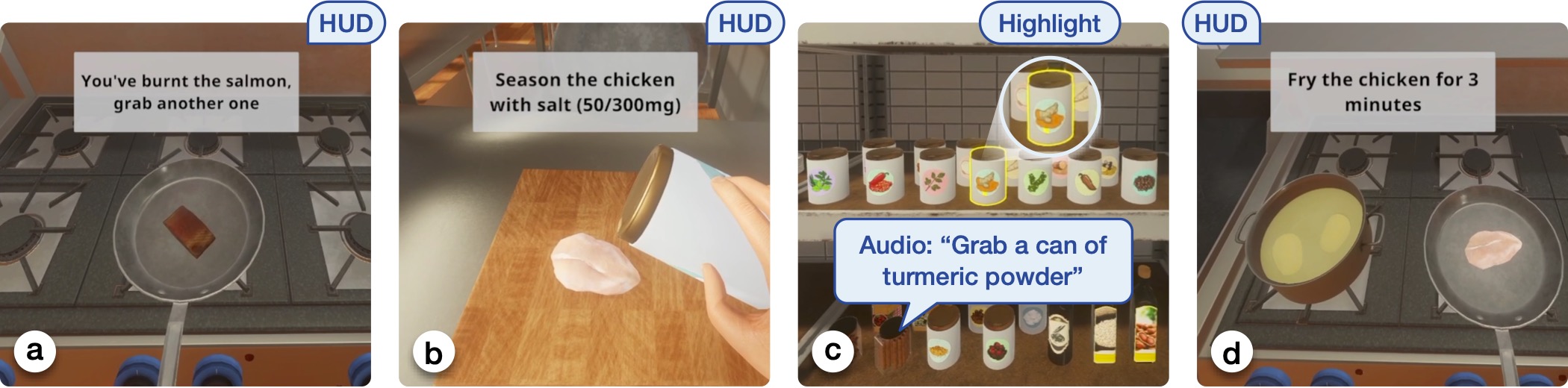
Cooking Assistant: An Example AMMA Application
To demonstrate the effectiveness of AMMA, we built a cooking assistant running in a high-fidelity virtual reality (VR) simulator. The cooking assistant adapts its guidance and communication modalities based on the user’s progress, preferences, and capabilities. We conducted a user study with 12 participants to evaluate the cooking assistant. The study protocol involved a training session, a personalization session to train the user model, and two experimental sessions comparing AMMA with a baseline system.
Evaluation Results
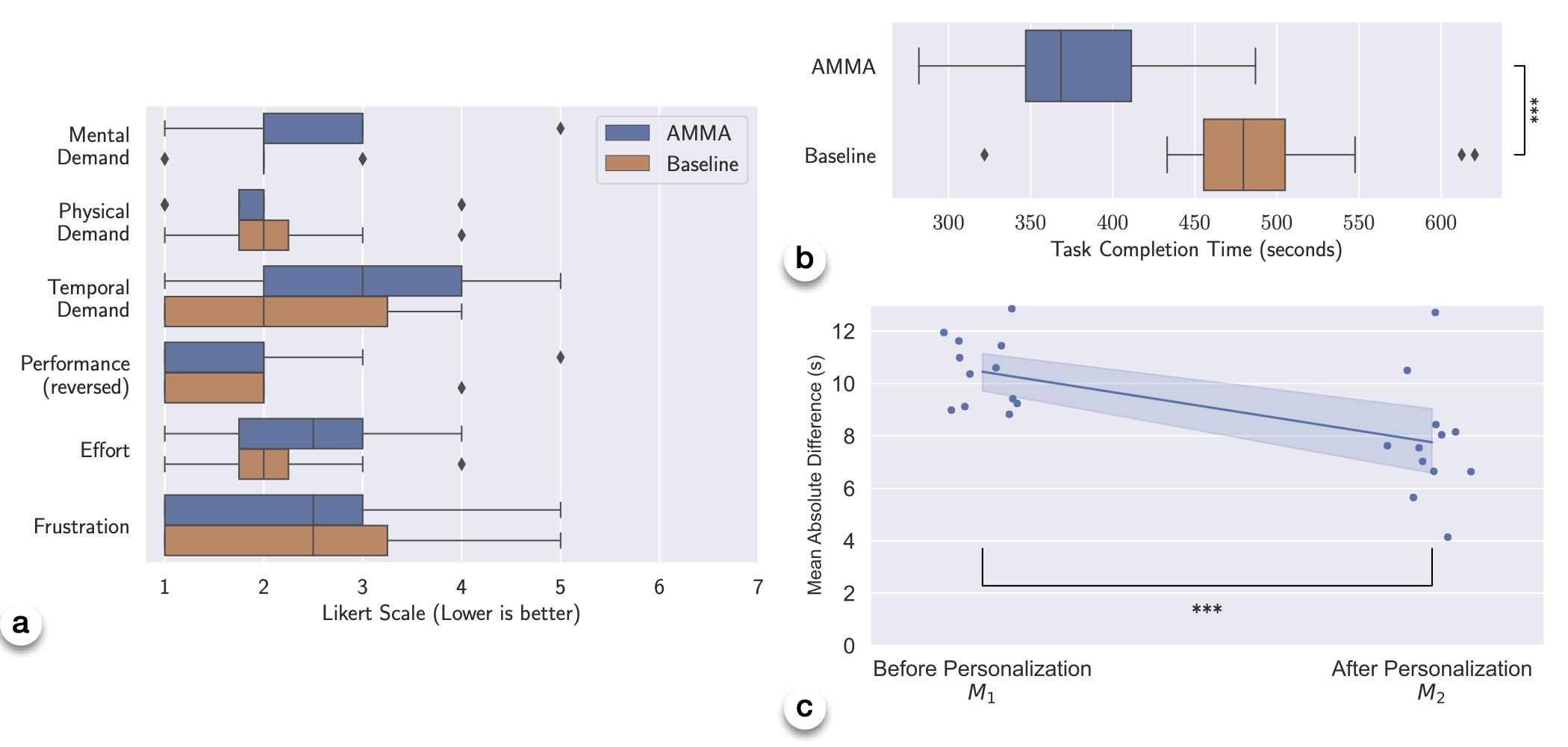
The user study showed that AMMA significantly reduces task completion time compared to the baseline system. Users spent an average of 380.2 seconds cooking with AMMA, while they spent 487.6 seconds with the baseline system (p < 0.001). AMMA had minimal effect on the users’ perceived task load, as measured by the NASA-TLX questionnaire. The median task load scores for AMMA and the baseline were 13.5 and 11.5, respectively (not statistically significant).
To shed some insights into the system’s inner workings, we found that the accuracy of estimation of the user model improved significantly after the personalization session. The mean absolute error of the user model’s predicted completion time (per step) decreased from 10.45 seconds before personalization to 7.76 seconds after personalization (p < 0.001).
Conclusion
AMMA demonstrates the potential for adaptive multimodal assistants to help users perform tasks more efficiently by adapting to their progress, preferences, and capabilities. By choosing the right abstraction – developers provide task-specific multimodal input and output, while AMMA generates a state tracker and a user model-based guidance planner – AMMA enables the creation of adaptive interfaces that can be applied to a wide range of domains. As AR and other novel interface technologies continue to advance, AMMA provides a promising framework for building intelligent guidance systems that can learn from and adapt to individual users, ultimately enhancing the user experience and task performance.
Video preview
DOI link: https://doi.org/10.1109/VR58804.2024.00108
Citation: Jackie (Junrui) Yang, Leping Qiu, Emmanuel Angel Corona-Moreno, Louisa Shi, Hung Bui, Monica S. Lam, and James A. Landay. 2024. AMMA: Adaptive Multimodal Assistants Through Automated State Tracking and User Model-Directed Guidance Planning. 2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR). https://doi.org/10.1109/VR58804.2024.00108
Paper PDF: https://jackieyang.me/files/amma.pdf
Code Repo: Cooking Assistant (made with AMMA)