Soundr
Jackie (Junrui) Yang, Gaurab Banerjee, Vishesh Gupta, Monica S. Lam, James A. Landay
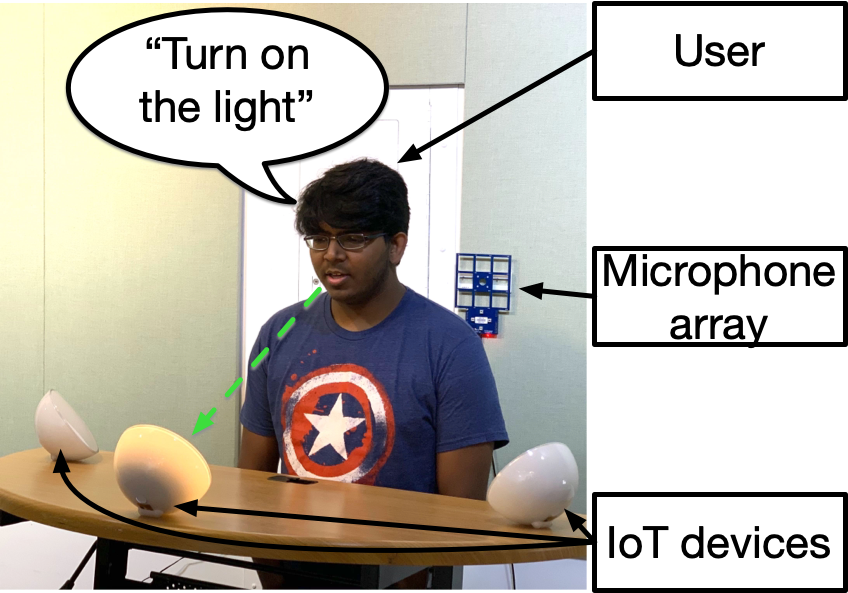
Although state-of-the-art smart speakers can hear a user’s speech, unlike a human assistant these devices cannot figure out users’ verbal references based on their head location and orientation. Soundr presents a novel interaction technique that leverages the built-in microphone array found in most smart speakers to infer the user’s spatial location and head orientation using only their voice. With that extra information, Soundr can figure out users references to objects, people, and locations based on the speakers’ gaze, and also provide relative directions. To provide training data for our neural network, we collected 751 minutes of data (50x that of the best prior work) from human speakers leveraging a virtual reality headset to accurately provide head tracking ground truth. Our results achieve an average positional error of 0.31m and an orientation angle accuracy of 34.3° for each voice command. A user study to evaluate user preferences for controlling IoT appliances by talking at them found this new approach to be fast and easy to use.
DOI link: https://doi.org/10.1145/3313831.3376427
Citation: Jackie (Junrui) Yang, Gaurab Banerjee, Vishesh Gupta, Monica S. Lam, and James A. Landay. 2020. Soundr: Head Position and Orientation Prediction Using a Microphone Array. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery, New York, NY, USA, 1–12. https://doi.org/10.1145/3313831.3376427
Paper PDF: https://jackieyang.me/files/soundr.pdf
Code: https://github.com/stanford-soundr
Video preview
Paper talk